
MySQL
基础篇
知识概括
windows查看mysql版本(三种方法):windows查看mysql版本(三种方法)_cmd查看mysql版本-CSDN博客
用MySQL之前记得先启动MySQL
客户端连接(win+cmd)之前记得先配置mysql\bin目录到环境变量中
- 语法:mysql -u root -p
- 如果出现版本号说明连接成功
DBMS:数据库管理系统
关系型数据库(RDBMS)
- 概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库
char(10):定长字符串(其余位置用空格来填充) varchar(10):变长字符串
图形界面化工具:Datagrip
- 注意:连接MySQL时需要启动MySQL,且密码和MySQL当时设置的密码一致
sql
sql语句不区分大小写,但关键词建议用大写
注释
- 单行注释:用”–” 或 “#”
- 多行注释:用/* */
SQL分类
DDL:数据定义语言,用来定义数据库对象(数据库,表,字段)
- 查询所有数据库show databases; 查询当前数据库select database();
- 查询表结构
- 语法:desc 表名;
- 查询指定表的建表语句
- 语法:SHOW CREATE TABLE 表名;
- 创建表
- 语法:create table 表名{字段 字段类型;······}
- 删除表
- 语法:drop table 表名
- 使用表
- 语法:use table 表名
- 添加字段
- 语法:ALTER TABLE 表名 add 字段名 类型(长度) [COMMENT注释] [约束];
- 修改数据类型
- 语法:ALTER TABLE 表名 modify 字段名 新数据类型(长度);
- 修改字段名和字段类型
- 语法:ALTER TABIE 表名 change 旧字段名 新字段名 类型(长度) [COMIMENT注释] [约束];
- 删除字段
- 语法:ALTER TABLF 表名 drop 字段名;
- 修改表名
- 语法:ALTER TABLE 表名 rename to 新表名;
- 删除表
- 语法:drop TABLE [ IF EXISTS] 表名;
- 删除指定表,并重新创建该表
- 语法:runcate TABLE 表名;
DML:数据操作语言,用来对数据库表中的数据进行增删改
添加数据:insert
给指定字段添加数据
- 语法:insert into 表名 (字段名1,字段名2,…) values (值1,值2,.…);
给全部字段添加数据
- 语法:insert into 表名 values (值1,值2,…);
修改数据:update
- 语法:update 表名 SET 字段名1=值1,字段名2=值2,…[ where条件];
注意:修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表该字段名下的所有数据
- 语法:update 表名 SET 字段名1=值1,字段名2=值2,…[ where条件];
删除数据:delete
- 语法:delete from 表名 [where条件];
注意:delete语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据注意:delete语句不能删除某一个字段的值(可以使用update,用NULL),要删就是删一整行
- 语法:delete from 表名 [where条件];
DQL:数据查询语言,用来查询数据库中表的记录
查询多个字段
- select 字段1,字段2,字段3… from 表名;
- select * from 表名
去除重复记录
- select distinct 字段列表 from 表名;
条件查询的各种关键词
- 注意:where 字段名 like ‘_’(‘%’),模糊匹配
聚合函数
- 语法:select 聚合函数(字段列表) from 表名;
注意:所有的null值不参与聚合运算
- 语法:select 聚合函数(字段列表) from 表名;
分组查询
- 语法:select 字段列表 from 表名 [ where条件] group by 分组字段名〔having分组后过滤条件];
注意:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤注意:where不能对聚合函数进行判断,而having可以
- 语法:select 字段列表 from 表名 [ where条件] group by 分组字段名〔having分组后过滤条件];
排序查询
语法:select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2;
排序方式:
- ASC:升序(默认)
- DESC:降序
分页查询
- 语法:select 字段列表 from 表名 limit 起始索引,查询记录数;
DCL:数据控制语言,用来创建数据库用户、控制数据库的访问权限
查询用户
- use mysql; select * from user;
创建用户
- 语法:create user ‘用户名‘@‘主机名’ identified by ‘密码’;
修改用户密码
- 语法:alert user ‘用户名‘@’主机名’ indentified with mysql_native_password by ‘新密码’;
删除用户
- 语法:drop user ‘用户名‘@’主机名’;
注意:主机名可以使用**%**通配
函数
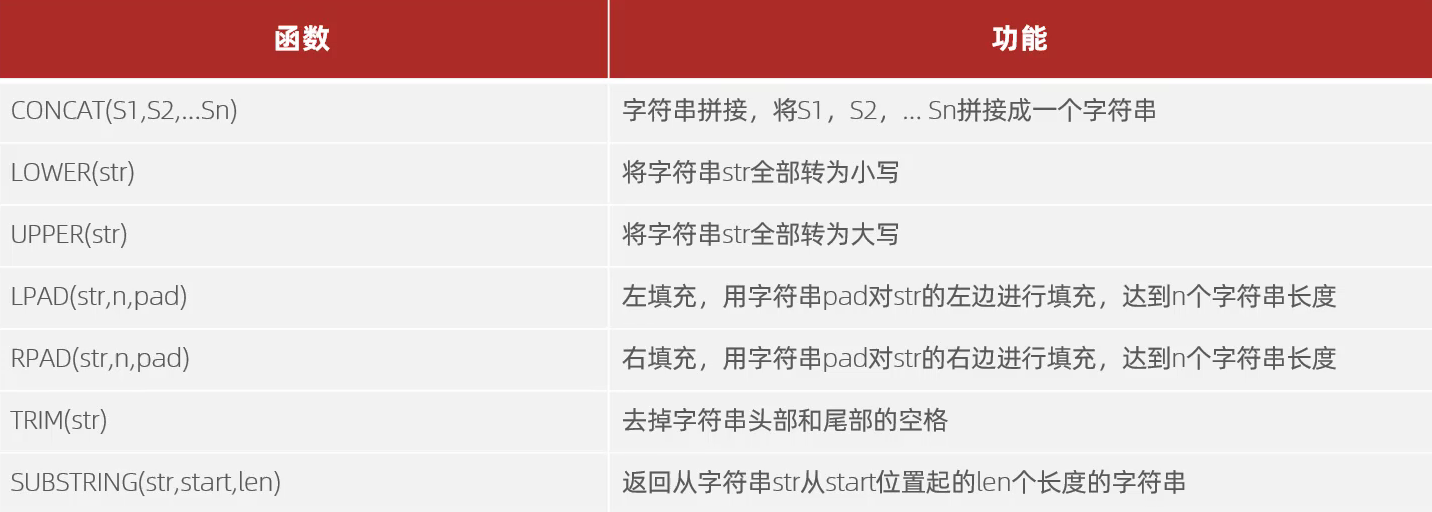
1、字符串函数
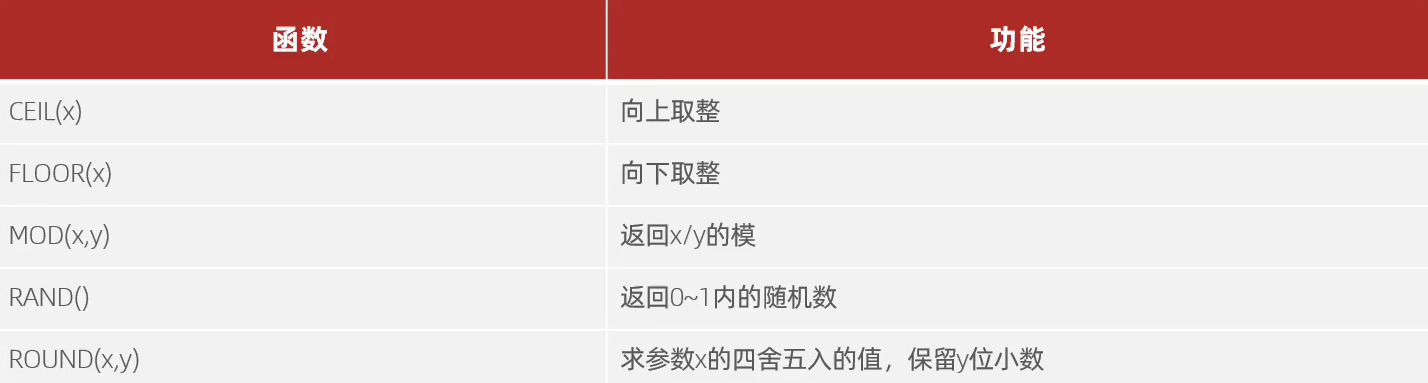
2、数值函数
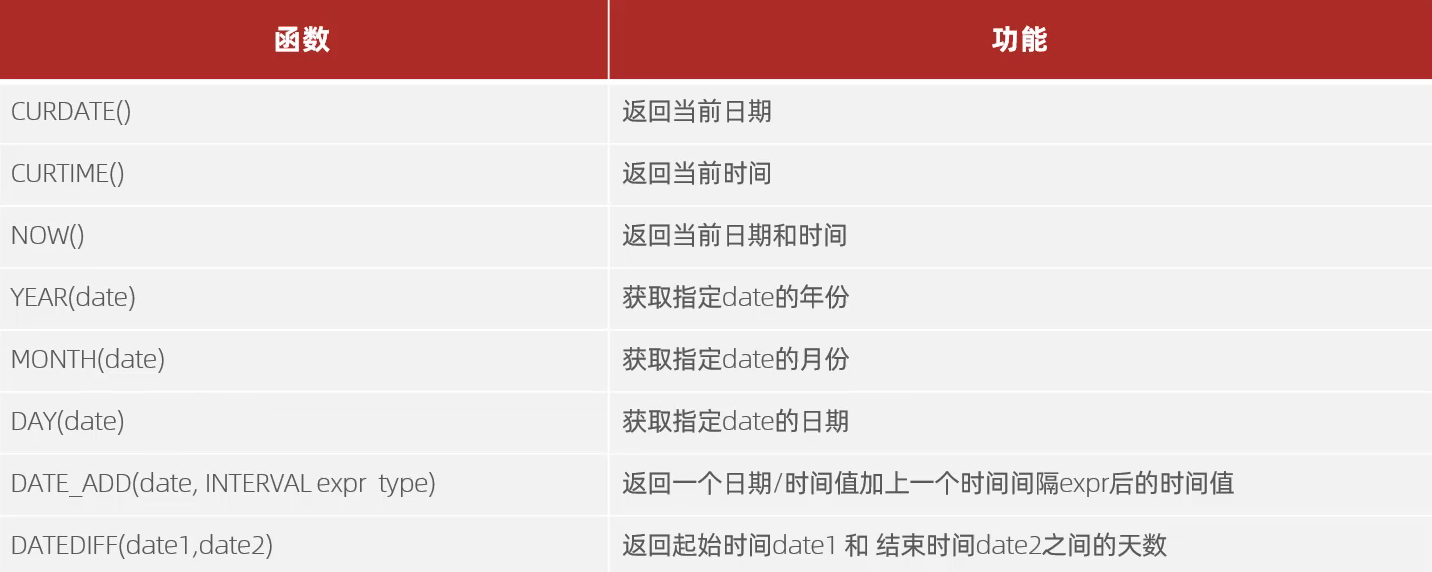
3、日期函数
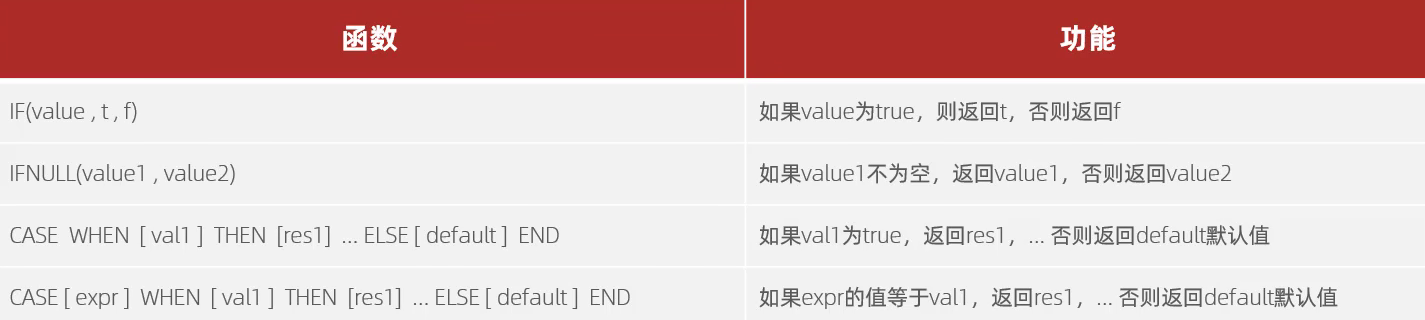
4、流程函数
约束
1、概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据
2、分类
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制改字段的数据不能为null | not null |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | default |
| 检查约束 | 保证字段值满足某一个条件 | check |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | foreign key |
外键约束
添加外键
- 语法:alert table 表名 add constraint 外键名称 foreign key (外键字段名)references 主表(主表列名);
删除外键
- 语法:alert table 表名 drop foreign key 外键名称;
多表查询
- 一对多(多对一)
- 实现:在多的一方建立外键,指向
一一方的主键
- 实现:在多的一方建立外键,指向
- 多对多
- 实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
- 一对一
- 实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(unique)
事务
1.概念:事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
查看/设置事务提交方式
- select @@autocommit
- set @@autocommit = 0; #设置事务提交为手动提交
开启事务
- 语法:start transaction 或 begin;
提交事务
- commit;
回滚事务
- rollback;
2.事务的四大特性(ACID)
- 原子性
- 事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性
- 事务完成时,必须使所有的数据都保持一致状态。
- 隔离性
- 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性
- 事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
3.并发事务问题
- 脏读
- 不可重复读
- 幻读
进阶篇
知识概括
1.MySQL的体系结构
- 连接层
- 最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
- 服务层
- 第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。
- 引擎层
- 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。
- 存储层
- 主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
2.存储引擎的选择
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
- MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
 微信
微信