
数仓开发学习笔记
数仓开发
ODS层(接入层/贴源层)
ods层用来对接数据源,同步用的
全量(full)——状态
增量(inc)——行为
业务分两大类:全量表和增量表
日志文件
业务表
- 全量表: DataX, 表结构与业务表保持一致
- mysql : column[id, name, age]
- data: 1001 zhangsan 30
- hive: column[id, name, age]
- 增量表: Maxwell
- JSON
- 最外层JSON对象的属性作为表的字段
- JSON
- 全量表: DataX, 表结构与业务表保持一致
DIM层
维度层保存维度表,所以建模理论应该遵循维度建模理论
维度层中的维度表,主要用于统计分析
- 数据存储方式应该为列式存储:orc
- 数据压缩效率越高越好(时间短):snappy
维度模型
- 维度(状态)表
- 事实(行为)表
事实表是用来做统计的
维度表是用来做分析的
全量维度表:以天为单位将数据全部同步到维度表的相同时间分区中

- 补全数据
- 补全行: union
- 补全列: join
如果不影响结果用left join, 不用join
分区覆盖:insert overwrite table dim_sku_full partition (dt=’2022-06-08’)
大部分的维度表都是全量的
shift+alt+鼠标左键可以多光标选中, shift + ctrl + alt可以矩形选中
行为是用来做统计的,状态是用来做分析的
实际生产环境中是用脚本来增加数据,没有事务的概念,所以不能回滚
拉链表的数据源是ods增量表
- 增量表
- maxwell
- 数据格式:json
- 同步方式:
- 首日:bootstrap(select)
- 每日:insert, update, delete(binlog)
- maxwell
首日全量, 每日增量
拉链表其实就是压缩
写窗口函数
row_number() over (partition by id order by start_date desc) rn
date_sub(‘2022-06-09’, 1) 天数减1天
?动态分区操作
规范化(雪花模型)
- 是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
反规范化(星型模型)
- 是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。在设计维度表时,如果对其进行规范化,得到的维度模型称为雪花模型,如果对其进行反规范化,得到的模型称为星型模型。
DWD层
英文全称是Data Warehouse Detail
对ODS层的数据进行加工,为后续的统计分析做准备
DIM层的主要功能主要是分析数据:面向状态
DWD层的主要功能主要是统计数据:面向行为
DWD层的表主要保存的就是业务行为数据, 表的设计需要遵循维度建模理论, 创建的表成为事实(行为)表
数据的存储格式:orc列式存储
数据的压缩格式:snappy
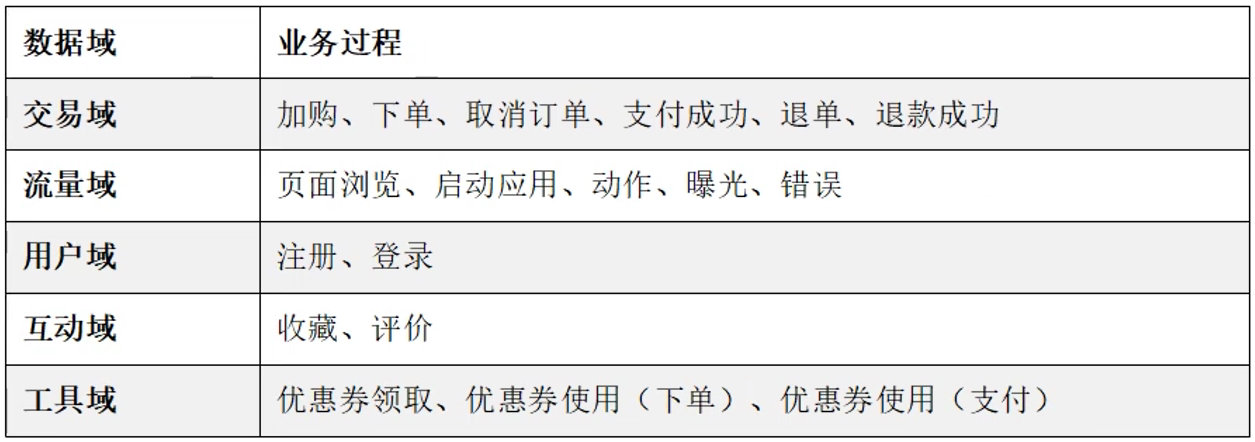
- 数仓项目所需的所有业务过程及数据域划分详情
事实表分类
- 事务事实表(绝大多数)
- 周期快照事实表
- 累计快照事实表
行为描述的详细程度称为粒度
- 维度越多,粒度越细
- 维度越少,粒度越粗
了解时间函数
- from_unixtime(ts, ‘yyyy-MM-dd HH:mm:ss’)
- date_format(from_utc_timestamp(ts*1000, ‘GMT+8’), ‘yyyy-MM-dd HH:mm:ss’)
ADS层
统计粒度:分析数据的具体角度,称之为统计粒度(站在哪一个角度统计数据)
指标:客户想要的一个结果数值
分组聚合的场合下,那些字段可以出现在select子句中
- 常量
- 聚合函数内的字段
- 参与分组的字段
多个字段参与分组的时候,统计值的含义
- 如果多个字段存在上下级,所属关系,那么统计结果和最下级字段相关,上级字段参与分组纯粹是用于补全数据
- 所属:例如省份与城市之间的关系
- 如果多个字段存在关联关系,那么统计结果和具有唯一性字段相关,其他字段纯粹是用于补全数据
- 关联:例如(id, name, …)这种
sql
数据视图只是保留一个调用(sql)
distinct是随机去重
对表起别名不需要用as,对字段取别名最好加上as
union会去重, union all不会去重
聚集函数
- sum
- max
- min
- avg
- count
count(*)和count(1)是一个意思,都会扫全表
having用在group by后面(having只用于聚合函数)
hive sql要对表加别名
join相当于是求交集
窗口函数
1 | -- row_number不能排名并列 |
sql里面的字符串下标索引是从1开始的,而不是从0
trim()函数去除空格
力扣SQL高频50
判断null写 is null,而不是写 =null
对于varchar类型的字符串,求字符串长度的函数为 char_length()
左连接left 表 on,条件跟在on后面,如果没有的用null补齐
datediff是 SQL 中用于计算两个日期之间的天数差的函数,DATEDIFF(结束日期, 开始日期),如果两个参数有任何一个为null则计算结果为null
timestampdiff(unit, start_datetime, end_datetime) 这个unit是时间单位(second, hour, day…)
cross join就是笛卡尔积
join on是默认的innner join内连接,只会匹配满足on条件中的行
IFNULL(AVG(c.action = ‘confirmed’), 0)的意思是如果AVG(c.action = ‘confirmed’)为null,则返回0
left on左连接,相同的字段不会合并为一列,还是仍然有两列
判断一个日期在某个范围之内可以用between … and …
where 只能用来过滤 join之后的结果,不能用来定义join的连接条件
在 MySQL 中,所有子查询都必须有别名,否则会报错。
date_format(date, ‘%Y-%m’)将日期按照年月输出,例如将2019-01-02转化成2019-01
格式化函数会在group之前执行,即使在select语句中
有 order by 时,distinct 先去重,再排序
1 | select Max(num) as num |
四舍五入函数用round
在select中,不能直接在其他计算中使用同一层的字段别名
1 | CASE |
1 | -- # Write your MySQL query statement below |
窗口函数(Window Function)是 SQL 中的一类特殊函数,它用于在查询结果中执行计算,但不会影响查询返回的行数。
跟group by不同的是, group by要合并行,但是窗口函数不会,仍然保留每行的数据
常见窗口函数:
- sum() over():在窗口内求和
- avg() over():在窗口内求平均
- row_number() over():计算当前行在窗口内的编号(编号唯一)
- rank() over():计算当前行在窗口内的排名(相同值的排名一样,后续排名会跳过)
- dense_rank() over():无跳跃排名
- lag() over():获取前一行数据
- lead() over():获取后一行数据
窗口函数知识点:
- rows 6 preceding:表示当前行及其前6 行组成窗口
- preceding表示前
- following表示后
1 | SELECT employee_id, department, salary, |
cast(… as signed) 的作用是将 row_number() 的结果转换为 signed类型(有符号整数)
DESC排序时,NULL值排在最前面(null相当于无限大)
- desc nulls last可以将null值排在最后
ASC排序时,NULL值排在最后面
- acs nulls first
union会自动去重
在mysql中substr对字符串索引的下标从1开始
date_sub(date, INTERVAL value unit) 从date日期中减去时间
union all的效率比union更好,因为union有去重的功能(可能底层用缓存来实现去重的逻辑)
date()函数,返回提取日期时间值的日期部分(去掉时间部分)
sql经典题
- 查询连续登陆的用户
- 思路就是用lag和lead开窗,如果date(log_time)与前一天的差值为1,与后一天的差值为-1,那么就说明是连续的三天
1 | select |
DWS层
dws层用来预聚合,保存中间计算结果
dws层的数据存储格式为orc列式存储,+ snappy压缩
命名规范为dws _ 数据域 _ 统计粒度 _ 业务过程 _ 统计周期(1d/nd/td)
- 1d表示最近1日,nd表示最近n日,td表示历史至今
大数据组件
spark
Spark + Hive => shark =>
- Spark on Hive => SparkSQL
- Hive on Spark => Hive -> SQL -> RDD(数据仓库)
Hive
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能
Hive的本质是一个hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序
内部表和外部表的区别:
- 内部表(管理表):意味着Hive会完全接管该表,包括元数据和HDFS中的数据
- 外部表:意味着Hive只接管元数据,而不完全接管HDFS中的数据
cast(‘111’ as int)函数可以完成显示类型的转换
建表有
- create table as select 表(CTAS建表)这种方式不能选择创建外部表,所以默认是内部表
- create table like 表
 微信
微信