
分布式计算系统
Hadoop
HDFS的存储思想
- 文件分块存储:将大文件分成块,块的大小设置为128mb,这些文件块可以分布到集群中不同的节点上,令多个节点对逻辑层面的大文件在物理层面进行分布式存储
- 分块冗余存储:HDFS将大文件切分成块,每个小块同时进行冗余备份
- 简化文件读写:一次写入,多次读取,可避免读写冲突
NameNode是如何备份的
edits、fsimage
Secondary NameNode来做定期的元数据的合并,让edits文件的部分合并到fsimage中去,保证内存比较小
HA高可用
文件的读写
block的拆分是在客户端中进行的
代码
hadoop fs || hdfs dfs
MapReduce(批处理)

Map(<k,v>键值对) -> Reduce中间有Shuffle阶段如何将相同的k值合并到同一个reduce就用哈希取模将k值进行数字编码然后模上个数
每个block块会启动一个Map任务
每个reduce任务会输出一个结果文件,存放在一个数据目录下
combine方法是一种“局部”的reduce操作,好处:不仅能降低Map和Reduce任务消耗的存储空间,还能够有利于降低Shuffle过程中传输的数据量
关系表自然连接
- map和reduce
- 如果一张表非常大一张表非常小怎么处理:通过MapReduce提供的分布式缓存机制对较小的关系表进行广播来解决,可以避免Shuffle过程,为整个关系表的连接带来了性能的提升
Spark(批处理)
- Spark基于RDD(弹性分布式数据集)进行计算
- RDD是只读的,对原RDD进行修改之后要用新的RDD来保存
- RDD的操作算子(创建操作算子、转换操作算子、行动操作算子)

- 主从结构
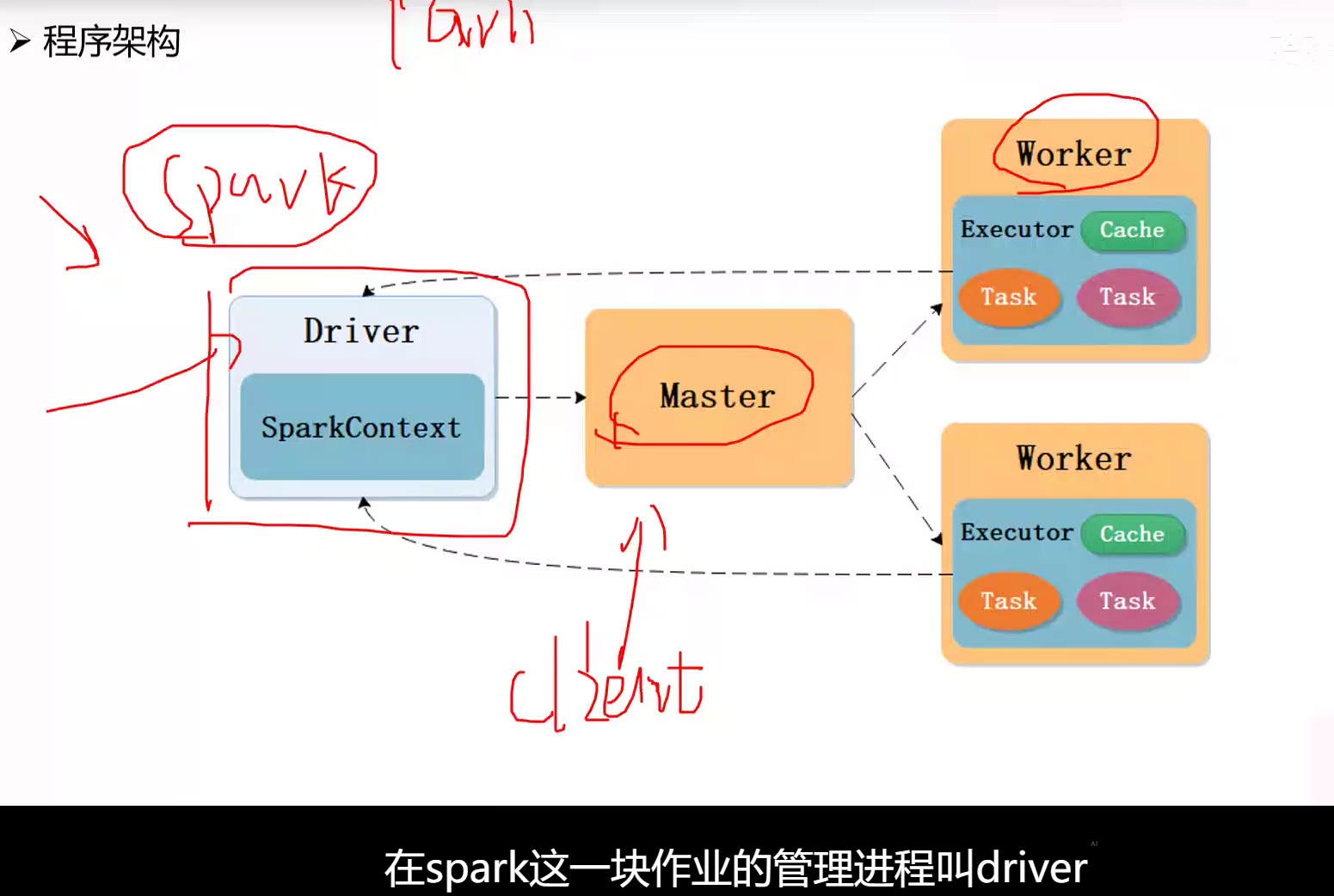
- Spark可分为Standalone和Yarn两种模式
- Standalone集群管理器包含Master和Worker
- Yarn集群管理器包含ResourceManager和NodeManager
- 集群管理器负责集群资源管理,而驱动器负责作业管理
- RDD之间存在依赖关系,窄依赖是一对一,宽依赖是多对一
- RDD的持久化:
- 原因:因为计算过程会不断产生新的RDD,因此系统无法将所有的RDD均存储于内存中,内存是有限的,所以要持久化
- 调用RDD的persist(Storagelevel)方法或cache()方法实现持久化
- 在Lineage较长尤其存在宽依赖时,需要在适当的时机设置数据检查点
- 检查点机制将RDD写入可靠的外部分布式文件系统,例如HDFS。如果用户指定某些RDD需要设置检查点,则系统将在作业结束之后启动一个独立的作业进行写检查点操作
- 检查点机制作用:防止因RDD Lineage过长而导致恢复过程中重计算的开销过大
- 关系表自然连接中,Spark提供广播变量机制,将较小的关系表作为广播变量进行广播
Yarn(资源管理系统)
FIFO(先进先出调度器)
- 调度策略:将所有任务放入一个队列,先进队列的先获得资源,排在后面的任务只有等待
- 缺点:资源利用率低,无法交叉运行任务,一个应用独占所有资源而其他应用需要不断等待,以及灵活性差,如紧急任务无法插队,耗时长的任务拖慢耗时短的任务
capacity(容量调度器)
- 调度策略:集群资源由多个队列分享,每个队列都要预设资源分配的比例,空闲资源优先分配给“实际资源/预算资源”比值最低的队列,队列内部采用FIFO调度策略
- 特点:
- 层次化的队列设计:子队列可使用父队列资源
- 容量保证:每个队列都要预设资源占比,防止资源独占,
- 弹性分配:空闲资源可以分配给任何队列,当多个队列争用时,会按比例进行平衡
- 支持动态管理:可以动态调整队列的容量、权限等参数,也可动态增加、暂停队列
- 访问控制:用户只能向自己的队列中提交任务,不能访问其他队列
- 多租户:多用户共享集群资源
Fair(公平调度器)
- 调度策略:多队列公平共享集群资源,通过平分的方式,动态分配资源,无需预先设定资源分配比例,队列内部可配置调度策略:FIFO、Fair(默认)
- 特点:
- 资源抢占:终止其他队列的任务,使其让出所占资源,然后将资源分配给占用资源量少于最小资源量限制的队列
- 队列权重:当队列中有任务等待,并且集群中有空闲资源时,每个队列可以根据权重获得不同比例的空闲资源
Storm(流计算系统)
- 数据模型:将流数据看作一个无界的、连续的元组序列
- Storm使用拓扑抽象描述计算过程,拓扑是由Spout和Bolt组成的网格
- Bolt中可执行过滤、聚合、查询数据库等操作对元组进行转换,并将处理后的元组作为新的流数据发送给其他Bolt
- Storm以Executor作为工作线程而在Task中仅实现任务代码
- Storm的ACK机制用于确保消息处理的可靠性,保证每个消息都会被至少处理一次
- 词频统计中的ShuffleGrouping和FieldsGrouping
Spark Streaming(实时流计算系统)
- Spark Streaming采用微批处理方式,将连续的流数据进行切片(按时间间隔离散化),生成一系列小块数据
- 增量式是避免重复计算
- 数据检查点旨在加快执行器发生故障后的恢复过程
- 元数据检查点旨在保证驱动器能够从故障中恢复到正常状态
Flink(批流融合系统)
- Flink程序使用DataStream类表示无界数据,其为一个可以包含重复项的不可变数据集合
- DataSet和DataStream的区别
- 相同:记录是不可变的
- 不同:DataSet是有界的,而DataStream是无界的
- 在Standalone模式下,除客户端外,Flink系统仅具有JobManager和TaskManager
- 在Standalone模式下,当用户使用客户端提交Flink应用程序时,可以选择Attached方式或者Detached方式
- Attached提交方式下客户端与JobManager保持连接,可以获取关于应用程序执行的信息
- Dettached提交方式下客户端与JobManager断开连接,无法获取关于应用程序执行的信息
- Flink使用Chaining机制进行优化,将部分算子合并为一个”大“的算子,可以避免数据在不同TaskManager之间的非必要传输
- 状态管理
- 原因:在个别节点发生故障的情况下自定义于内存中的数据结构将会丢失,故障恢复需要将过去所有数据重新计算
- 状态:状态可以看作操作算子的记忆能力,可以保留已处理记录的结果,并对后续记录的处理造成影响
- map是一种典型的无状态算子,sum、window为有状态算子
- 非迭代计算过程的容错
- 异步屏障快照算法:通过在输入数据中注入屏障并异步地保存快照,达到和在同一时刻保存所有算子状态到检查点相同的目的
sb分布式Teacher(点名yqe),平时只有签到啥都没,一次作业没布置过,平时分给85。。期末第一次做题。期末画重点把整本书都画了但是只考了一部分 。(Yarn和Storm没考)最后一周期末周安排实验课,整整上了两天上午8点到下午5点,最开始布置了50个实验,因为太多,有同学去反应砍了一些,但还是很多,巨多。没法只能通宵!肝了两整天90多页word吧(唉,早知道不花这么多时间写这些傻逼报告了,准备期末不好嘛。。选择>>努力)这学期活的真窝囊啊,一直连着写了20多天的报告。刚刚好马原考前一天结束了大部分报告(最后剩了一门计网的大作业报告)。最后一天开始复习,看来马原居然还是复习得最久的!(仅一天罢了)。果不其然这学期炸了,没好好复习的结果,数据结构连基数排序是啥都不知道,直接送了15分~
扯远了,我还记得一些些,来简单复盘一下:
考的大致如下,全是一些画流程图的,一次没做过咋画()G
- 每个大题好像都有两个小问, 第一问是八股文,背书就行,就例如请写出HDFS上传文件的过程,什么是宽依赖什么是窄依赖等
- 每个大题的第二问都是类似画出流程图的,因为每个题都是个实际的问题,就例如请用MapReduce来处理、Spark来处理…等
- 依稀记得我们考了HDFS文件的读取操作
- MapReduce操作+分析画图
- Spark操作+分析画图
- Spark Streaming操作+分析画图
- Flink操作+分析画图
- 每个题好像20分?记不太清了反正(1)好像都是5分
- 然后(1)我记得的考了HDFS读文件操作,简述什么是宽依赖什么是窄依赖,简述Chaining机制,Flink中的状态管理是什么。我记得的只有这些了
 微信
微信